Несмотря на то, что в цифровую эпоху все идет в цифровую форму, вы возможно заметили, что бумага не исчезла. У нас все еще есть стопки распечаток, книг, счетов, листовок, журналов, выписок и других газет, с которыми нам приходится иметь дело ежедневно.
- Как текстовые документы могут идти в ногу с текущими технологическими изменениями
- Программы для распознавания текста из изображений
- Программы для распознавания текста из изображений для Ubuntu
- Readiris 17
- ABBYY FineReader 14
- Microsoft OneNote (бесплатно)
- Simple OCR (Free)
- Free OCR
- Boxoft Free OCR (Бесплатно)
- Top OCR (Платный)
- ABBYY FineReader Online (бесплатно)
- Распознавание текста онлайн
Как текстовые документы могут идти в ногу с текущими технологическими изменениями
Вот тут-то и появляется оптическое распознавание символов (OCR). Программное обеспечение OCR позволяет оцифровывать печатные или рукописные документы, делая их редактируемыми с помощью программ обработки текста.
Оптическое распознавание символов (OCR) — это программа, которая может конвертировать отсканированные, распечатанные или рукописные файлы изображений в машиночитаемый текстовый формат. Или если говорить более просто это программы для распознавания текста из изображений.
Возможно, у вас есть книга или квитанция, которую вы напечатали или напечатали несколько лет назад, и вы хотите, чтобы она была в цифровом формате, но вы не хотите ее перепечатывать. OCR может быть очень полезным в таком случае.
В этой статье, мы поговорим про лучшие программы для распознавания текста из изображений. Это основной вопрос, который у вас может возникнуть перед загрузкой OCR. Мы поможем вам выбрать, ответив на более конкретные вопросы:
- Поддерживает ли программа несколько форматов файлов?
- Есть ли в программе OCR распознавание разных языков?
- Можете ли вы использовать инструмент OCR онлайн?
- Распознает ли текст из файлов изображений?
Программы для распознавания текста из изображений
Сразу стоит отметить, что в этом списке, присутствуют программы не только для Ubuntu но и с поддержкой Windows/macOS.
Программы для распознавания текста из изображений для Ubuntu
- GOCR.
- CLARA.
- OCRAD.
- KOOKA.
- OCRFeeder.
- Tesseract.
Чтобы запустить Tesseract Goto откройте Terminal и введите следующее
tesseract imagefile.tif outputfile.txt
Readiris 17
Readiris 17 — последняя версия этого высокопроизводительного программного обеспечения для распознавания текста. Он поставляется с новым интерфейсом, новым механизмом распознавания и более быстрым управлением документами. Вы можете легко конвертировать во многие различные форматы, в том числе в аудиофайлы благодаря его устному распознаванию.
Readiris — это одно из самых мощных программ для распознавания текста, которое требует меньше усилий для начала работы. Хотя это платная программа, вы получаете то, за что платите. Readiris поддерживает большинство форматов файлов и поставляется с другими привлекательными функциями, которые упрощают процесс преобразования.
Например, изображения могут быть получены из подключенных устройств, таких как сканеры, и приложение также позволяет настраивать параметры обработки, такие как настройки DPI.
После завершения обработки Readiris определяет текстовые разделы или зоны и позволяет извлекать тексты либо из определенной зоны, либо из всего файла.
Readiris имеет редкую функцию сохранения в облаке, которая позволяет пользователям сохранять извлеченный текст в различные сервисы облачного хранения, такие как Google Drive, OneDrive, Dropbox и другие.
Он также имеет множество функций редактирования и обработки текста, что позволяет пользователям даже сканировать штрих-коды. Подписка начинается от 99 долларов, и предоставляется 10-дневная бесплатная пробная версия. Использование программы на Ubuntu возможно через Wine.
ABBYY FineReader 14
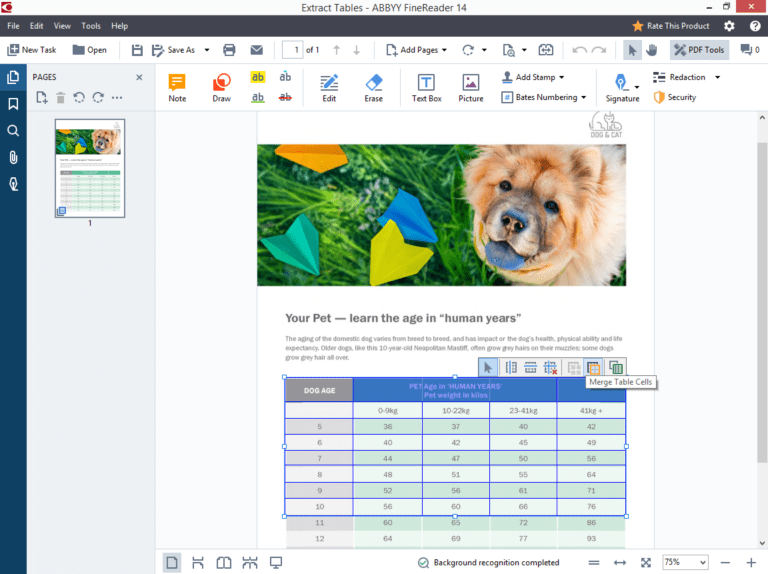
ABBYY FineReader 14 — это самое мощное программное обеспечение для распознавания текста на рынке и лучший инструмент для тех, кому нужно быстрое и точное распознавание текста.
Этот оптический распознаватель прекрасно справляется с работой с большими объемами и оснащен передовыми инструментами коррекции для сложных задач.
Превосходный инструмент проверки легко исправляет сомнительные показания, делая аккуратное сравнение между текстами OCR и оригиналом.
ABBYY Finereader 14 делает больше, чем вы ожидаете от распознавания текста. Вы хотите конвертировать старую книгу на 500 страниц в PDF с возможностью поиска? ABBYY справится с этим с максимальной точностью.
ABBYY извлечет самые точные тексты из изображений, найденных в Интернете.
Кроме того, он может конвертировать отсканированный документ в HTML или в формат ePub, используемый электронными читателями. Использование программы на Ubuntu возможно через Wine.
Microsoft OneNote (бесплатно)
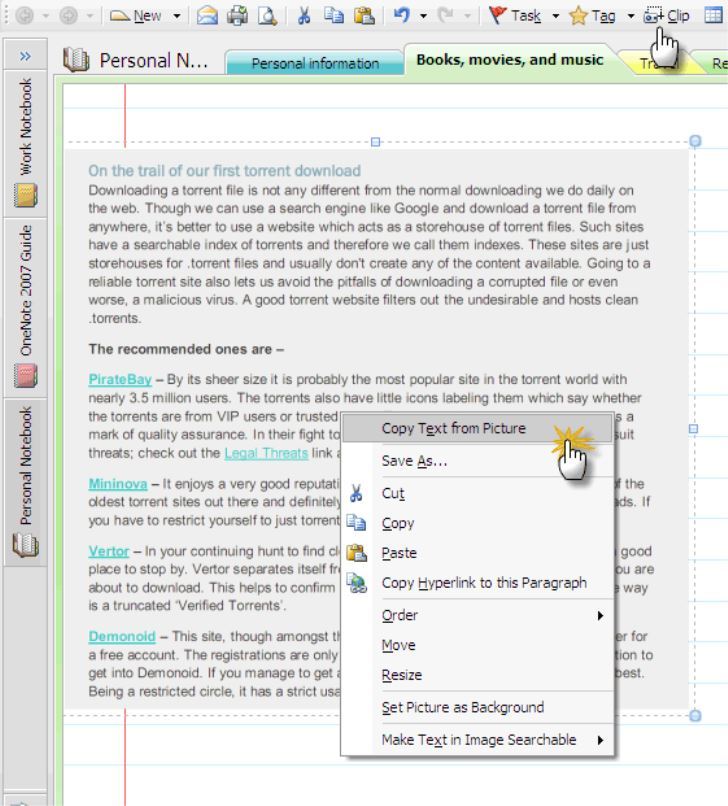
Microsoft OneNote также можно использовать в качестве OCR, несмотря на его функциональность в качестве хранителя заметок. Существует опция «Копировать текст из изображения», которая позволяет извлекать текст из изображений.
Его простота — вот что делает его уникальным; просто вставьте картинку в OneNote, затем щелкните правой кнопкой мыши на картинке и выберите «Копировать текст из картинки», а OneNote сделает все остальное. Он сохраняет текст в буфер обмена, а затем вы можете вставить текст в Microsoft Word или любую другую программу по вашему выбору.
Тем не менее, он не поддерживает таблицы и столбцы. Использование программы на Ubuntu возможно через Wine.
Simple OCR (Free)
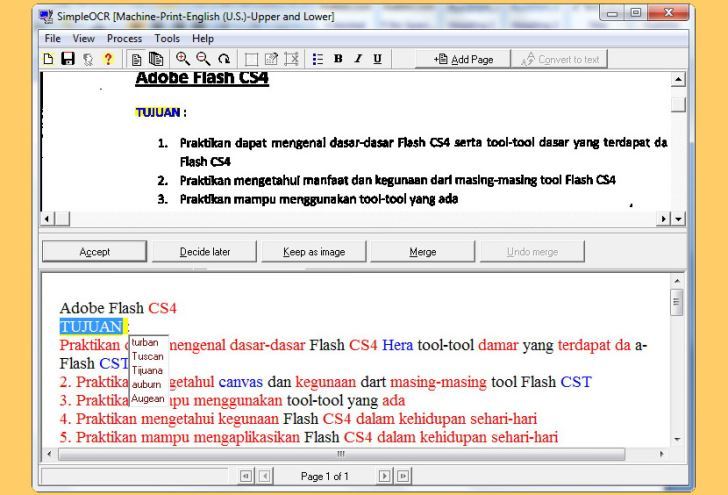
Если говорить про программы для распознавания текста из изображений, то это приложение является очень удобным. Simple OCR — это удобный инструмент, который вы можете использовать для преобразования распечаток в печатном виде в редактируемые текстовые файлы.
Если у вас много рукописных документов и вы хотите преобразовать их в редактируемые текстовые файлы, тогда Simple OCR будет вашим лучшим вариантом.
Тем не менее, рукописное извлечение имеет ограничения и предлагается только как 14-дневная бесплатная пробная версия. Машинная печать бесплатна и не имеет ограничений.
Существует встроенная проверка орфографии, которую вы можете использовать для проверки расхождений в преобразованном тексте. Вы также можете настроить программное обеспечение для чтения непосредственно со сканера.
Как и Microsoft OneNote, Simple OCR не поддерживает таблицы и столбцы. Использование программы на Ubuntu возможно через Wine.
Free OCR
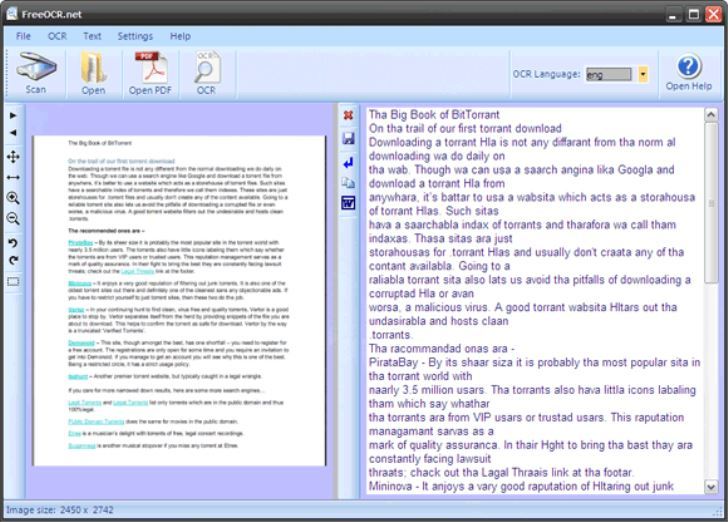
Free OCR использует Tesseract Engine, который был создан HP и теперь поддерживается Google.
Tesseract — очень мощный движок, и сегодня он считается одним из самых точных механизмов распознавания текста в мире. Free OCR отлично справляется с форматами PDF и поддерживает устройства TWAIN, такие как цифровые камеры и сканеры изображений.
Кроме того, он поддерживает практически все известные файлы изображений и многостраничные файлы TIFF. Вы можете использовать программное обеспечение для извлечения текста из картинок, и оно делает это с высокой степенью точности.
И, как и другое программное обеспечение Free OCR, Free OCR не поддерживает вывод таблиц и столбцов.
Boxoft Free OCR (Бесплатно)
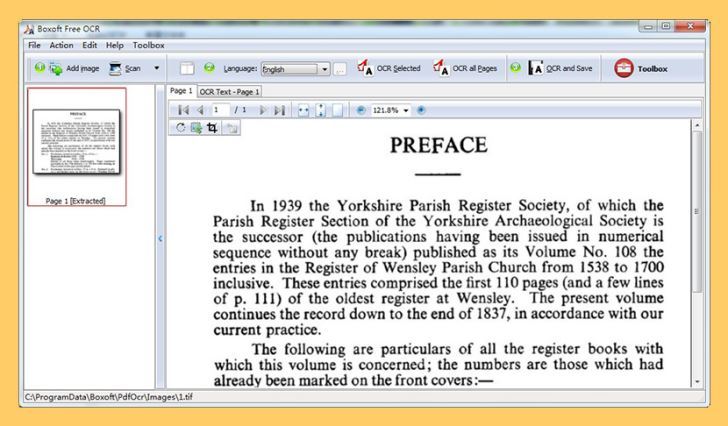
Boxoft Free OCR — еще один удобный инструмент, который вы можете использовать для извлечения текста из всех видов изображений.
Эта бесплатная программа проста в использовании и способна анализировать многостолбцовый текст с высокой степенью точности.
Он поддерживает несколько языков, включая английский, испанский, итальянский, голландский, немецкий, французский, португальский, баскский и многие другие.
Это программное обеспечение OCR позволяет вам сканировать ваши бумажные документы и конвертировать их в редактируемые тексты в течение очень короткого времени.
Хотя существуют опасения, что это средство распознавания текста не справляется с извлечением текста из рукописных заметок, оно исключительно хорошо работает с печатными копиями.
Top OCR (Платный)

TopOCR отличается от типичного программного обеспечения OCR во многих аспектах, но выполняет работу точно. Лучше всего работает с цифровыми камерами и сканерами. Если говорить про лучшие программы для распознавания текста из изображений, то обязательно стоит и рассказать про эту программу более детально.
Его интерфейс также отличается, поскольку у него есть два окна — окно изображения (источника) и текстовое окно.
Как только изображение получено с камеры или сканера с левой стороны, извлеченный текст появляется с правой стороны, где находится текстовый редактор.
Программное обеспечение поддерживает форматы GIF, JPEG, BMP и TIFF. Вывод также может быть преобразован в несколько форматов, включая PDF, HTML, TXT и RTF.
Программное обеспечение также поставляется с настройками фильтра камеры, которые можно применять для улучшения изображения.
ABBYY FineReader Online (бесплатно)
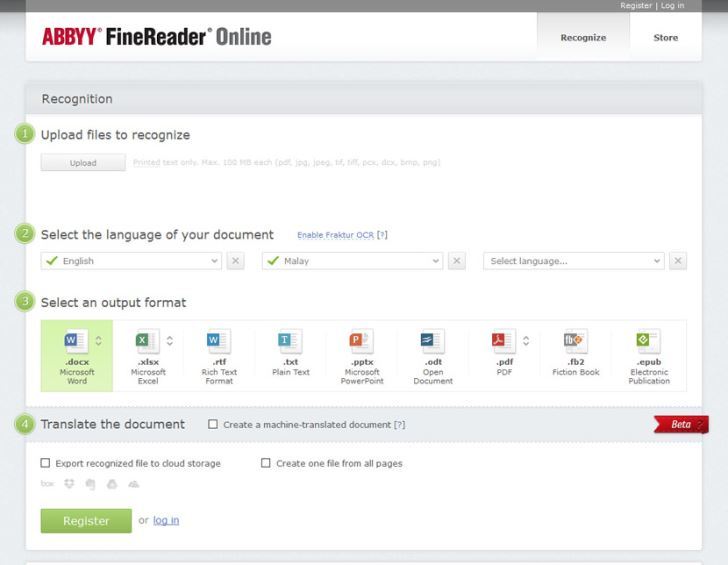
Если вы хотите насладиться мощными функциями, которые ABBYY предлагает, но не хотите идти дорогим путем, то вы можете попробовать бесплатную онлайн-версию.
FineReader Online поддерживает множество входных файлов, таких как PDF, JPEG, JPG, PNG, DCX, PCX, TIFF, TIF и BMP. Поддерживаемые выходные файлы включают PDF, Word, Excel, e-Pub и Powerpoint.
Бесплатная версия позволяет вам конвертировать до 10 страниц в месяц, и она требует сначала сделать регистрацию, которая также бесплатна.
Однако, если вы интенсивный пользователь и хотите конвертировать больше страниц в месяц, вам необходимо подписаться на платную версию.
Распознавание текста онлайн
Еще один отличный способ, это распознавать текст онлайн. Сайт img2txt предлагает очень удобный, легкий и быстрый для распознавания текста.
Готово! В этой статье, мы поговорили про лучшие программы для распознавания текста из изображений. Рынок наводнен программами OCR, которые могут извлекать текст из изображений и сэкономить вам много времени, которое вы могли бы потратить на перепечатывание документа.
Однако хорошие программы для распознавания текста из изображений должно делать больше, чем извлекать текст из печатных документов. Оно должно поддерживать макет, текстовые шрифты и текстовый формат в качестве исходного документа.
Мы надеемся, что эта статья поможет вам найти лучшее программное обеспечение для распознавания текста. Не стесняйтесь комментировать и делиться.





